ShellScriptでドヤりたいGWアドベントカレンダー6日目いくで。
よくある「open .」でFinderで開く方法ではなく、逆にFinderで開いているディレクトリをTerminalで開く。 何を言っているかよくわからないのでとりあえず動作デモ。
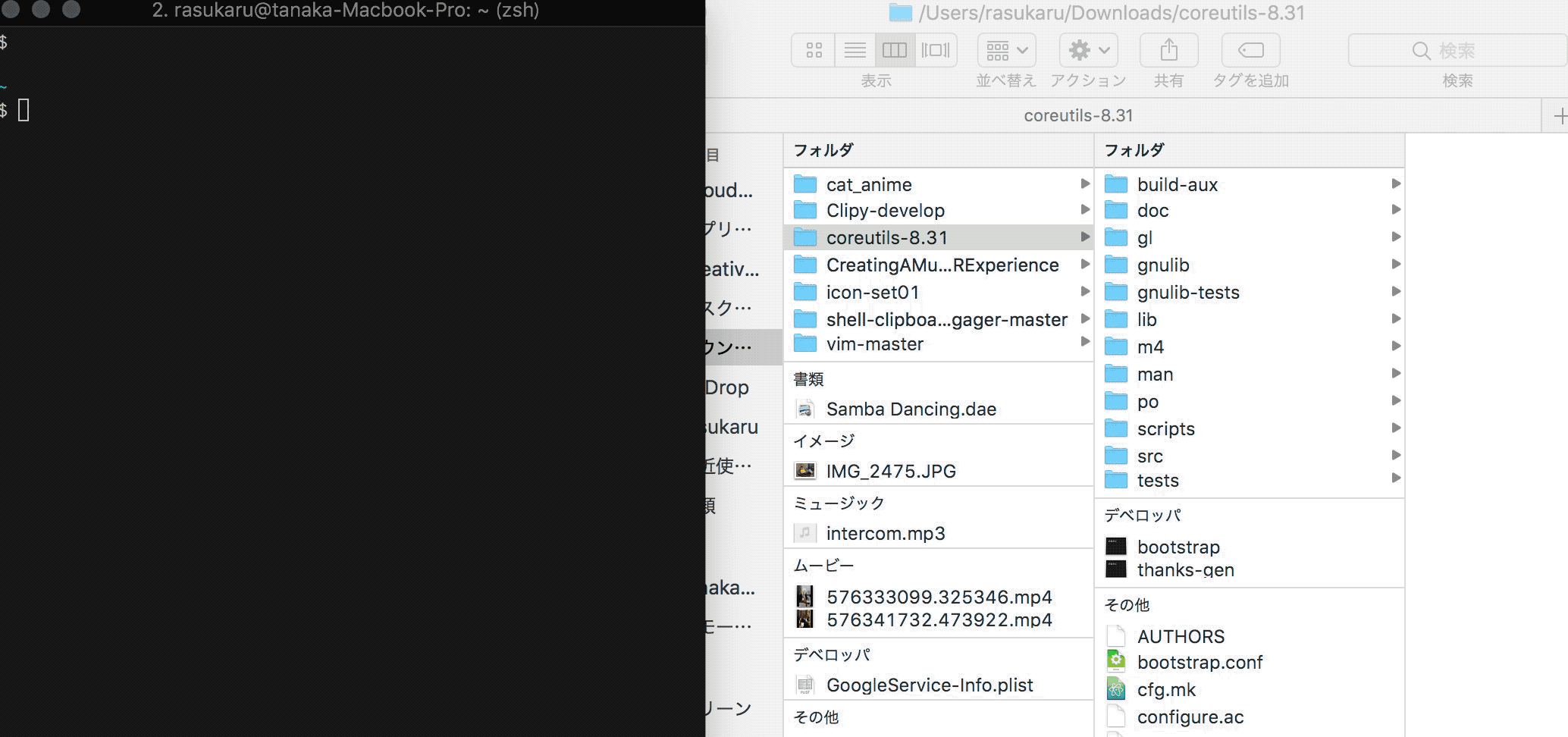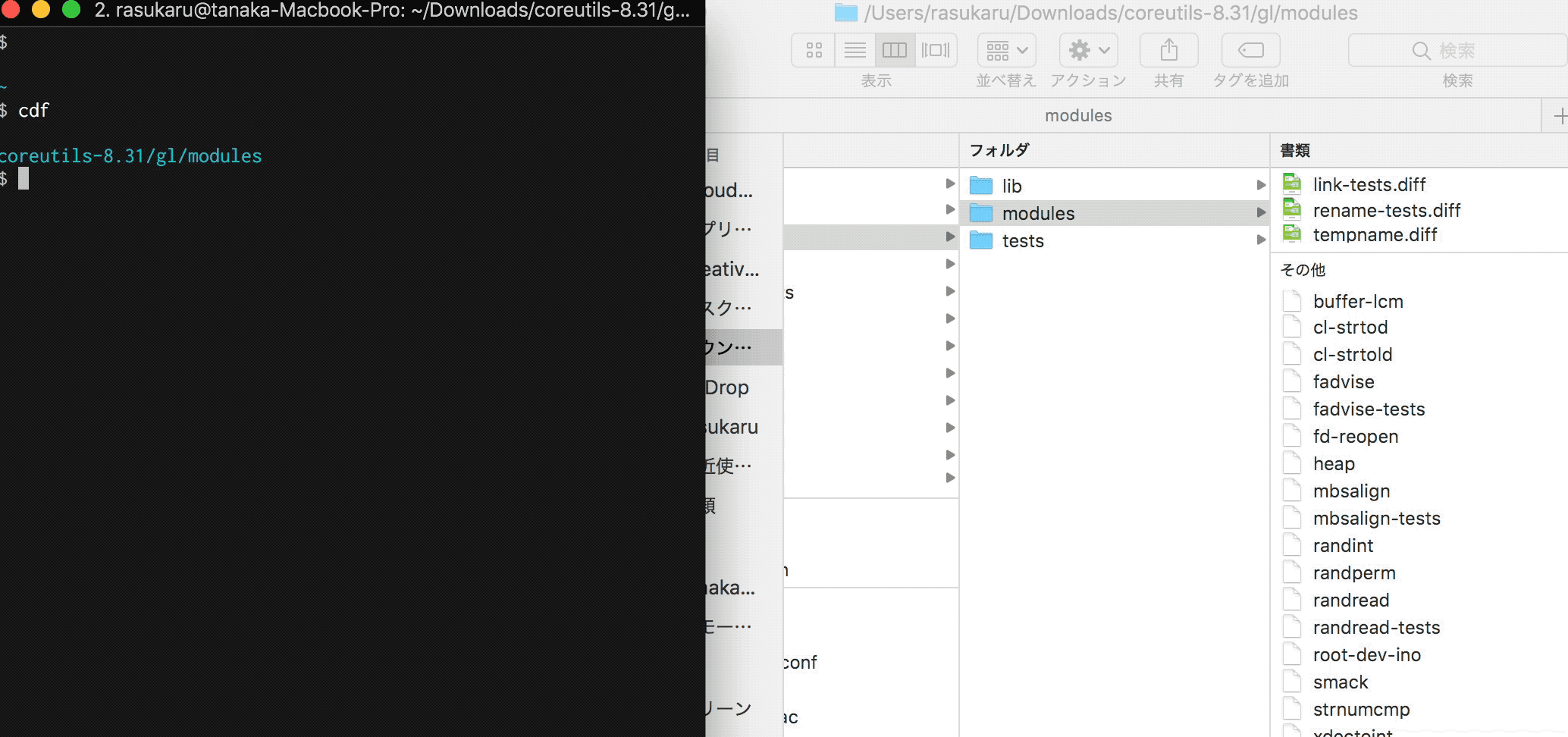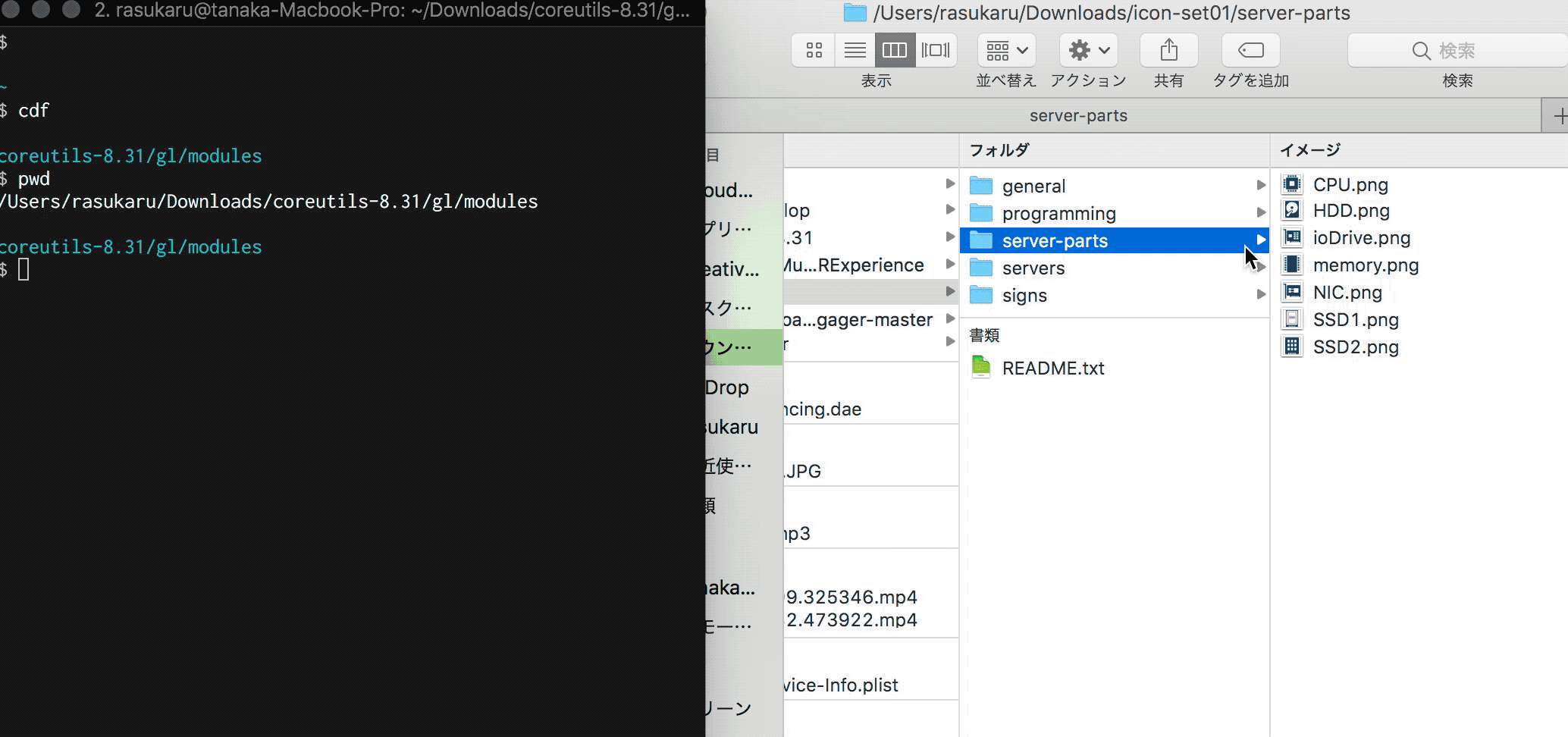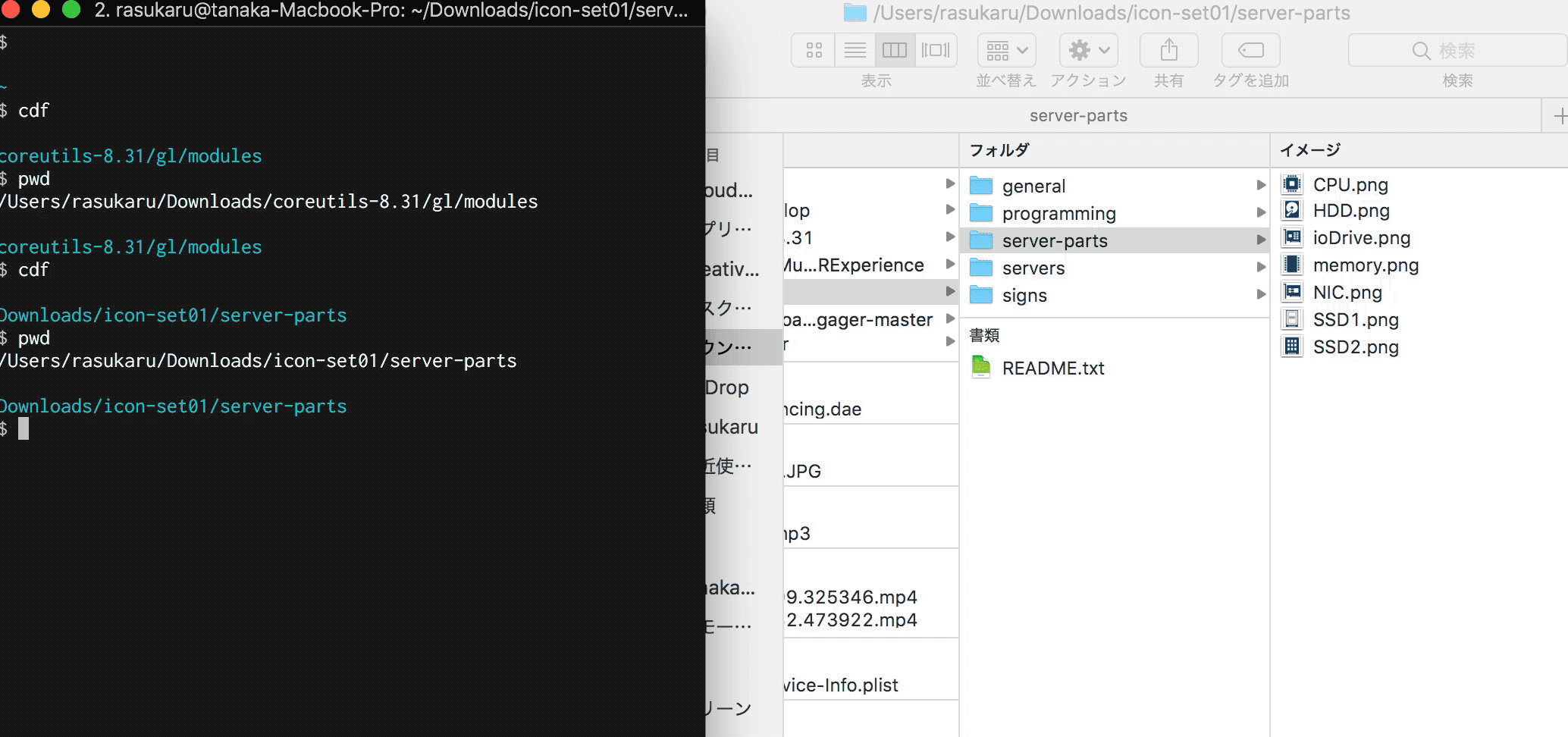
伝わるか・・・?Finderで今開いているディレクトリにTerminalで移動している。
何がしたいのか
僕はよくGithubでソースみたいときに、とりあえずZipでダウンロードしてChromeで、Finderのプレビューで少し眺めてから
詳しく見たいやつをVimで開くっていう流れが多い。
しかしFinderからTerminalに移動して、cd XXXX/YYYYとする際、今DLしたものの名前を覚えておく必要があり、そこを楽にしたかった。
(最初からgit cloneで持ってこいよという話はナシにしましょうね。)
Finderで今開いているパスを知りたい
大体なんとなくダウンロードしたディレクトリ名は覚えているから特に困りはしないのだが、
そもそも覚えていたくない。のでTerminalから取得できるようにする。
AppleScriptを使えば一発だ。
finder.sh
#!/usr/bin/osascript ## 現在Finderで開いているディレクトリのPATHを取得 tell application "Finder" if exists Finder window 1 then set currentDir to target of Finder window 1 as Unicode text set posixPath to get POSIX path of currentDir end if end tell
実行
$ osascript finder.sh /Users/rasukaru/Downloads/shell-clipboard-magager-master/
ネックなのがif exists Finder window 1 thenとしているので、Finderを複数開いている場合1番目に開いたFinderのディレクトリしか取得できない。
tell application "Finder" set total_num_finder to (count of (every window where visible is true) end tell
で今開いているFinderの数は取得できるので、うまいことやれば全部のディレクトリ取得できて、fzfに食わせればいい感じになるかもわからん。
Terminalから移動する
もうあとはaliasやら関数に登録して終了だ。あっけない。
.zshrc
alias cdf='cd $(osascript ~/finder.sh)'
Finderのツールバーにスクリプトを配置してもうちょっと楽(?)にする
ぶっちゃけあんまり使えないかもだが一応紹介しておく。
Commandを押しながらファイルをドラッグアンドドロップでFinderのツールバーに持っていくと、ツールバーに登録できる。ツールバーにあるものはクリックして実行が可能。
これを利用してTerminalに戻らずFinderから直接Terminalの画面に移ることができる。
ツールバー用のfinder.scptを作成する
ツールバー登録用としてfinder.scptを作成する。
finder.scpt
## 現在Finderで開いているディレクトリのPATHを取得 tell application "Finder" if exists Finder window 1 then set currentDir to target of Finder window 1 as Unicode text set posixPath to get POSIX path of currentDir end if end tell ## Terminal上でPATHへ移動する tell application "iTerm" activate set _current_session to current session of current window tell _current_session write text "cd " & posixPath end tell end tell
これをツールバーに登録して実行した挙動が以下。
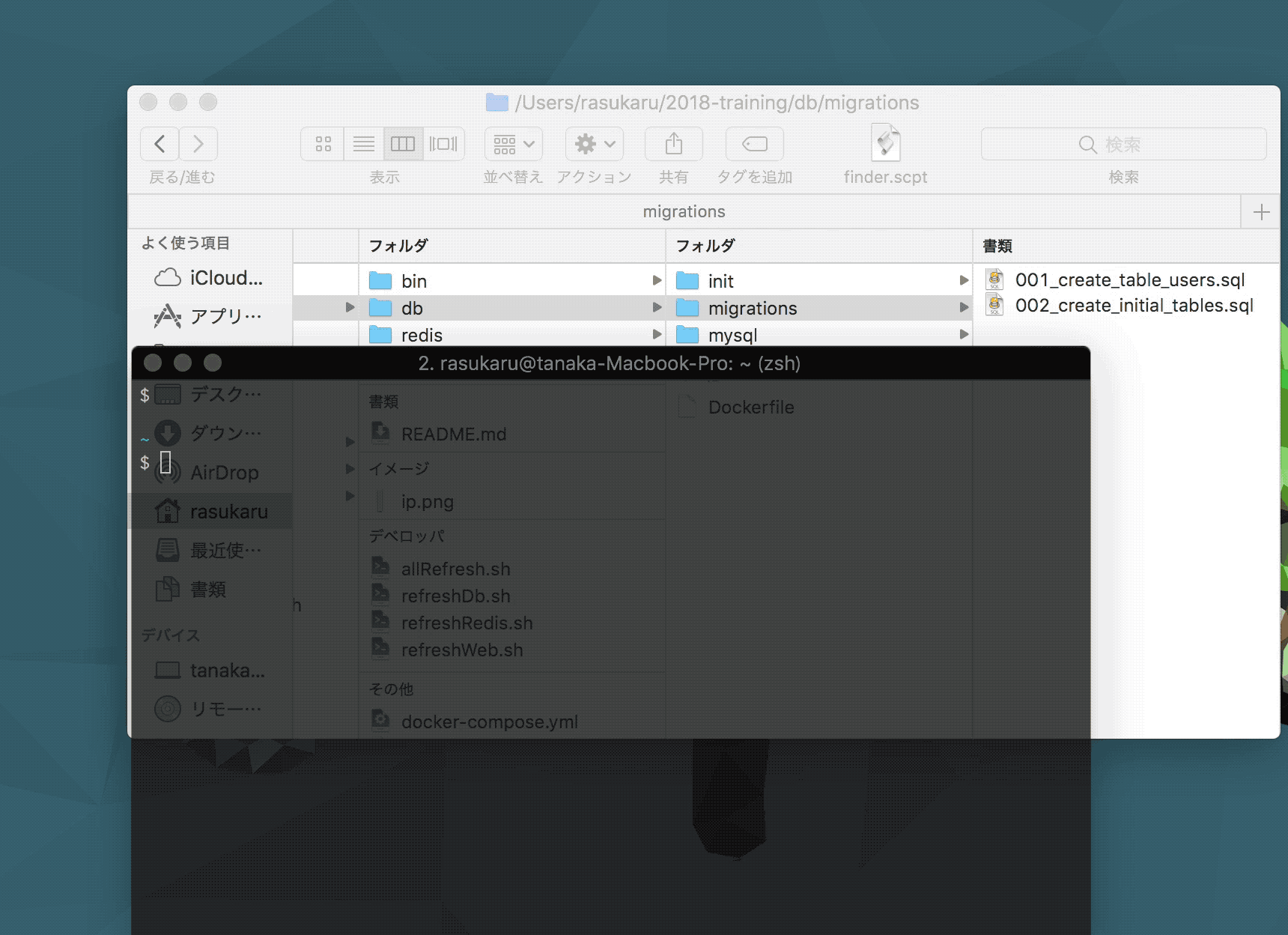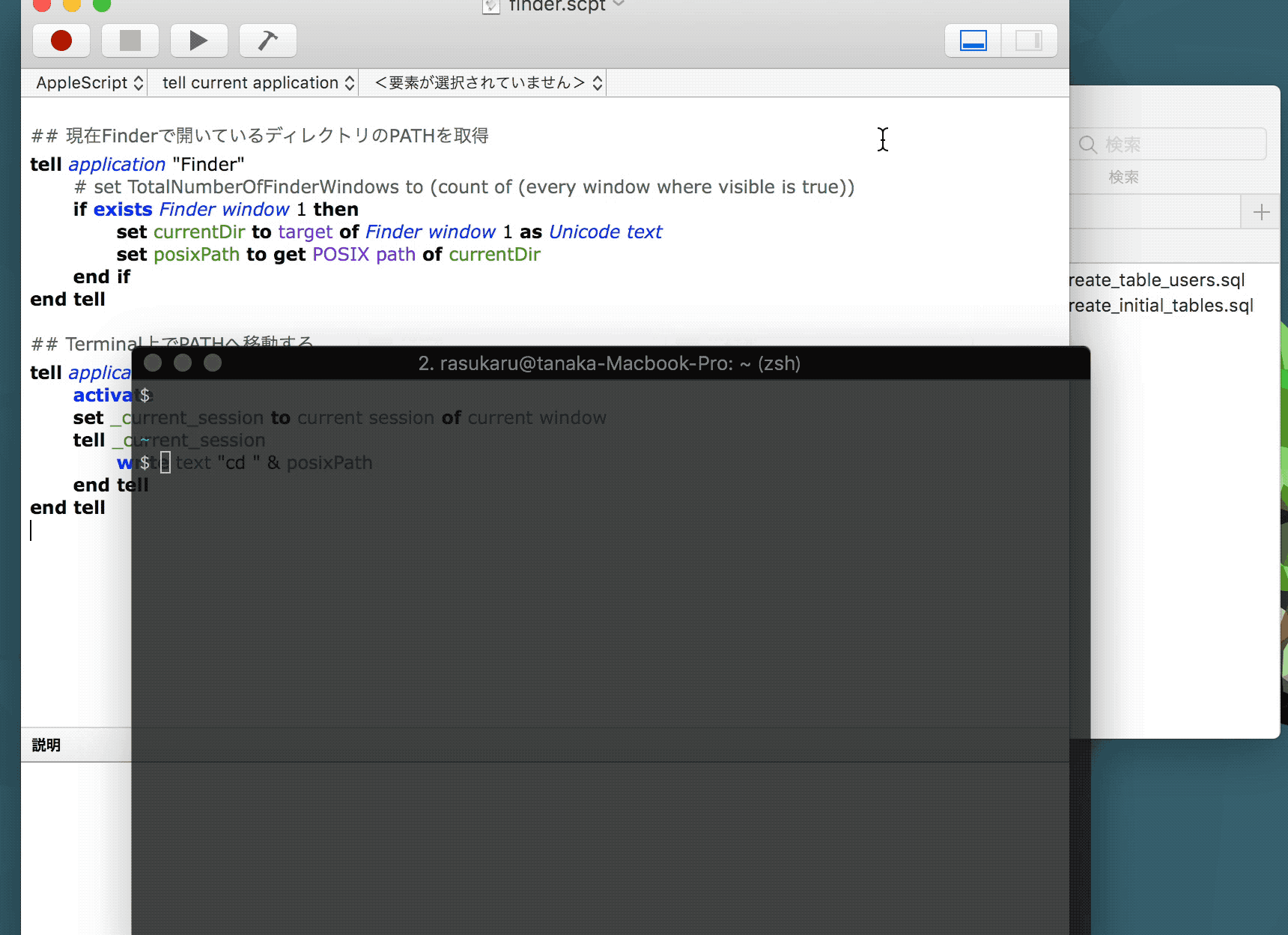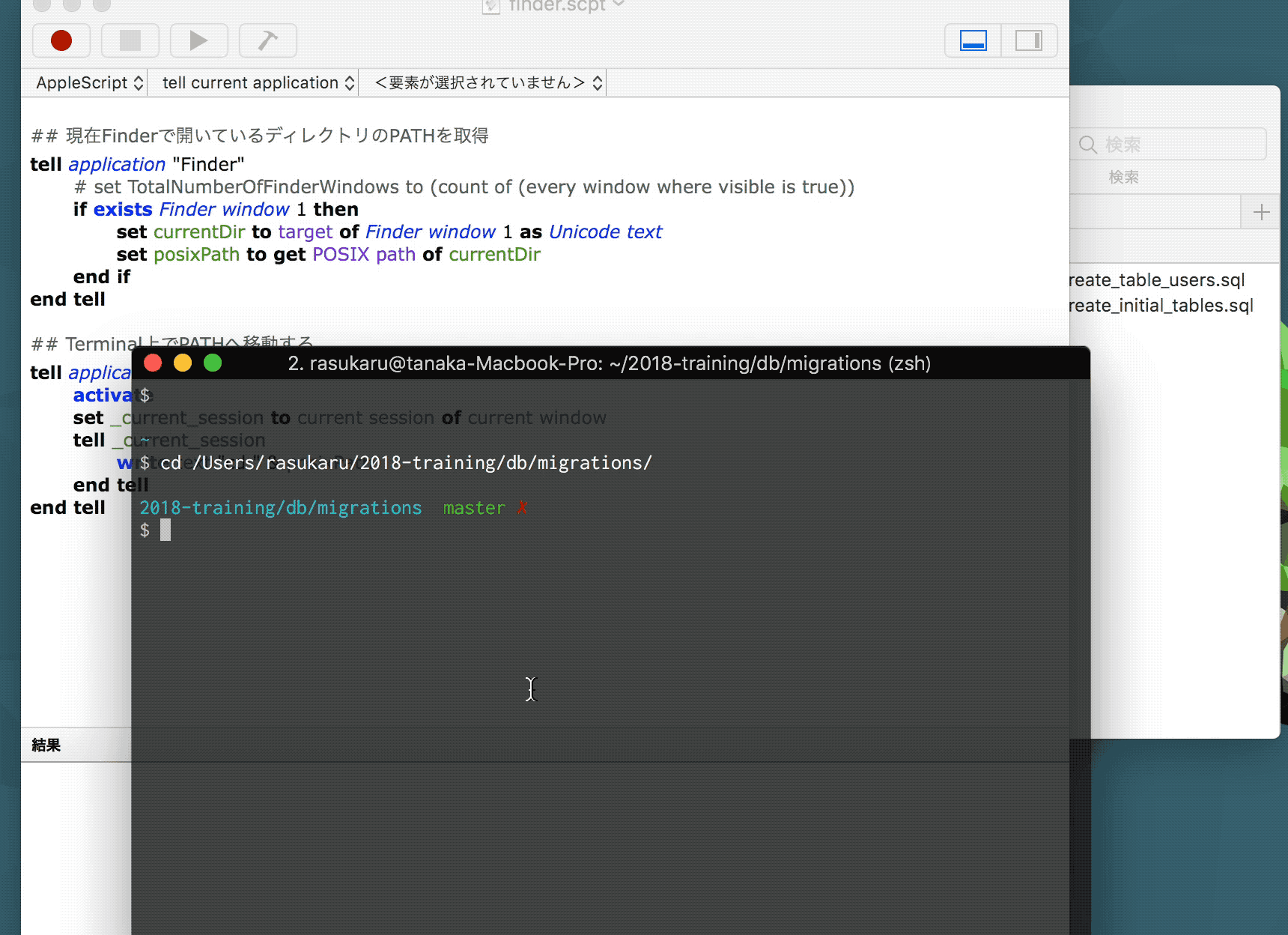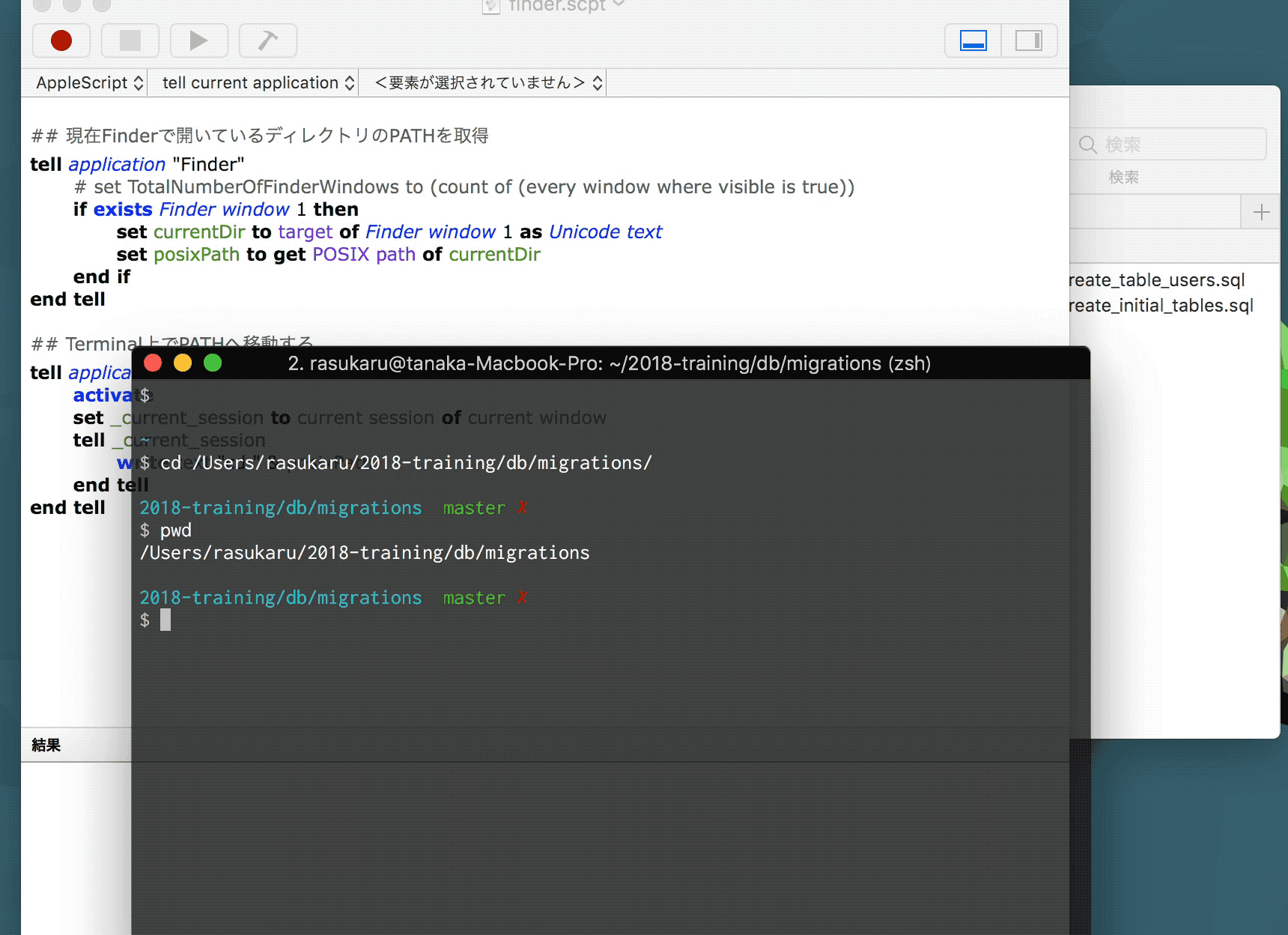
まあ、、、見事Terminalにいちいち戻らず移動できたわけだが問題点がいくつかある。
- finder.scptをクリックしたらいちいち「Run」を押さないと行けない
- Terminalに直接
cd XXXの命令を書き込んでいるので、VimなどをTerminalで開いていた場合そこにcdd XXXと書き込まれてしまう
・・・ゴミだな
終わり
まあなんとも言えない感じのものが出来上がってしまったが、作ったからにはアウトプットしておこうと思った。
ただ、Finderのツールバー登録は初めて知ったしもしかしたらアイデア次第で何か使えるかもしれん。
こんなふうに使っているよという人いたらぜひとも教えて欲しい。